At a Glance
- What the blog covers: a comprehensive blueprint for architecting production-grade Advanced RAG Techniques for generative AI.
- How it helps: explains pre-retrieval optimization, retrieval methods, post-retrieval refinement, and fault-tolerance.
- Strategic value: outlines types of AI agents and how data governance supports scalable GenAI.
- Business relevance: shows how to build RAG systems that are accurate, efficient, and trustworthy for enterprise use.
Introduction: Why RAG Matters in Production
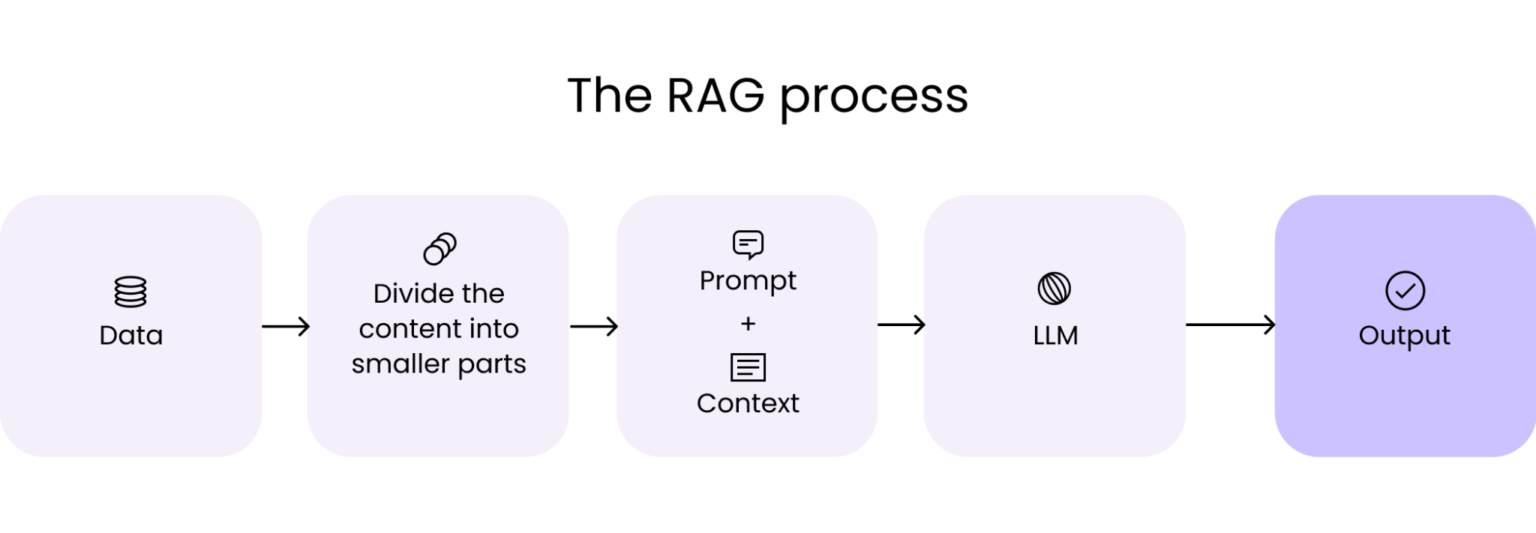
Retrieval-Augmented Generation (RAG) has become a cornerstone technique in modern generative AI systems. By combining powerful language models with external knowledge sources, RAG allows applications to produce responses grounded in factual, up-to-date data. But designing RAG systems for production is far more demanding than prototyping: enterprises require systems that are reliable, scalable, and governed.
This blog dives deeply into advanced RAG techniques — from pre-retrieval optimization and sophisticated retrieval strategies, to post-retrieval refinement, AI agents, and strong data governance — giving you the tools to build GenAI systems you can run in real-world environments.
1. RAG Pre-Retrieval Optimization: Laying the Foundation
Before you can generate high-quality text, you need to build a high-quality retrieval layer. This requires careful preparation of your data corpus, efficient storage, and powerful indexing.
1.1 Data Preparation & Cleaning
- Deduplication: Ensuring unique documents avoids redundant retrieval and inflated storage costs.
- Normalization: Transform text through lowercasing, lemmatization, and removal of punctuation so it’s consistent across fragments.
- Filtering: Use topic modeling or keyword-based heuristics to remove noisy or irrelevant data that may degrade generation quality.
1.2 Data Storage & Indexing
- Inverted Indexing: Standard search structure that maps terms to document positions enables efficient lookup.
- K-D Trees: Useful for multi-dimensional vector indexing when dealing with structured embeddings.
- HNSW (Hierarchical Navigable Small World): A graph structure that supports approximate nearest neighbor (ANN) search at scale, striking a balance between retrieval speed and accuracy.
By optimizing your data and index, you create a retrieval backbone that supports fast, targeted, and relevant document fetching — a prerequisite for high-quality generation downstream.
2. RAG Retrieval Optimization: Smart and Semantic Search
Once your corpus is indexed, you need to fetch relevant documents efficiently and accurately. This involves embedding-based retrieval, query reformulation, and efficient search algorithms.
2.1 Embedding-Based Retrieval
- Use transformer-based models (like BERT or Sentence-Transformer) to generate contextual embeddings of your documents and queries.
- Measure similarity using cosine similarity or Euclidean distance, which lets you retrieve semantically similar text rather than just keyword matches.
2.2 Query Expansion & Reformulation
- Synonym Expansion: Automatically expand user queries with synonyms or related terms to increase recall.
- Contextual Reformulation: Re-write query text using context to better align with how your documents are structured — for example, converting user intent into longer, more precise phrases.
2.3 Efficient Search Algorithms
- BM25: A tried-and-true probabilistic search ranking function that scores documents using term frequency, inverse document frequency, and length normalization.
- ANN Search Techniques: Use methods such as LSH or HNSW for fast retrieval in high-dimensional embedding space. These algorithms keep latency low while operating at scale.
By combining embedding-based retrieval with query refinement and optimized search, you ensure the retrieval module retrieves highly relevant context — which directly boosts the quality of generated responses.
3. RAG Post-Retrieval Optimization: Refining for Accuracy and Coherence
After retrieval, the next step is refining the outputs to ensure relevance, factuality, and user satisfaction. This is where post-retrieval optimization shines.
3.1 Reranking Retrieved Documents
- Learning to Rank (LTR): Train models (e.g., LambdaMART, RankNet, or BERT-based LTR) to sort retrieved documents by true relevance using features like BM25 score, embedding similarity, or metadata.
- Feature Engineering: Combine features such as semantic embedding similarity, BM25 scores, and document metadata to produce better re-ranking signals.
3.2 Fusion Strategies
- Score-Based Fusion: Combine relevance scores from different models (e.g., BM25, embedding-based, or neural ranking) by summing or weighting.
- Rank-Based Fusion: Use algorithms like COMB-SUM or COMB-MNZ to merge rank lists based on ranking positions.
- Hybrid Fusion: Create a robust final ordering by blending both score and rank fusion strategies.
3.3 Feedback and Reinforcement Learning
- Collect explicit feedback from users (e.g., thumbs-up/down, star ratings).
- Capture implicit feedback (clicks, dwell time, navigation patterns) to infer document relevance.
- Use reinforcement learning (e.g., Deep Q-Networks or policy gradients) to fine-tune retrieval and generation models over time, optimizing for user satisfaction and factual correctness.
Through reranking, fusion, and feedback loops, you can refine your RAG system to deliver content that’s not only relevant but consistently high-quality and context-aware.
4. Types of AI Agents in RAG-Enabled Systems
Modern generative AI systems often incorporate different classes of AI agents to serve various tasks. Understanding these helps you architect next-generation RAG applications.
| Agent Type | Purpose |
| Retriever Agent | Focuses purely on fetching relevant documents from the knowledge base before any generation occurs. |
| Generator Agent | Actually generates text by taking retrieved context and crafting a response using a language model. |
| Hybrid Agent | Combines both retrieval and generation in a single loop, often retrieving additional context mid-generation. |
| User-Interactive Agent | Allows real-time user feedback and correction, integrating reinforcement learning for continuous improvement. |
These agents can also orchestrate workflows: for instance, a retriever agent pulls relevant facts, a generator agent drafts content, and a feedback loop agent collects user corrections to refine future output. This architecture is frequently discussed in advanced RAG literature (e.g., Neo4j, Meilisearch) to boost usability, retrieval accuracy, and generation quality.
5. Data Governance: The Cornerstone of Production-Grade RAG
When deploying RAG systems in enterprise environments, data governance isn’t optional — it’s foundational. Ensuring trust in your RAG pipeline demands rigorous governance.
What Is Data Governance?
Data governance is the discipline of managing data’s usability, integrity, security, and availability throughout its lifecycle. It ensures that data used for retrieval is clean, reliable, compliant, and under proper access control.
Key Components of Data Governance
- Data Quality Management: Maintain high standards for cleaning, normalization, deduplication, and filtering.
- Access Controls & Security: Define who can access your corpus, who can modify it, and how sensitive documents are stored (e.g., encryption at rest).
- Lineage & Provenance Tracking: Record where data comes from, how it’s transformed, and how it’s indexed — enabling traceability.
- Compliance & Privacy: Implement policies and tools to anonymize personal data, comply with regulations (e.g., GDPR), and audit access.
- Lifecycle Management: Establish procedures for archiving, versioning, and removing obsolete or low-quality content.
By embedding data governance into RAG, you ensure that retrieved information is not only contextually relevant, but also accurate, ethical, and compliant — safeguarding user trust and minimizing legal risk.
6. Architecting a Production-Ready RAG System: Best Practices & Infrastructure
For your advanced RAG system to be truly production-ready, certain architectural and operational principles must be followed.
- Use distributed retrieval systems like Elasticsearch, Faiss, or Milvus to support large-scale, low-latency retrieval.
- Implement caching strategies and hot shard routing to handle frequent queries efficiently.
- Monitor retrieval latency, generation quality, and user feedback in real-time with dashboards and alerting systems.
- Build fallback and error handling: detect when retrieval fails or when generation produces incoherent or irrelevant answers, and fallback to safe defaults or human review.
- Scale horizontally: shard or replicate your index, balance query load across servers, and employ autoscaling to handle traffic spikes.
7. Monitoring, Logging & Feedback: Keeping Your RAG Healthy
Once in production, you need to continuously measure and improve. That means capturing telemetry, feedback, and quality signals.
- Log key metrics: query volume, retrieval latency, top-k ranking, embedding similarity scores.
- Track user interactions: clicks, dwell time, user corrections, or ratings.
- Retrain ranking models: periodically update your LTR system using new feedback data.
- Use reinforcement learning loops: deploy RL-based agents that fine-tune retrieval and generation policies based on performance and user satisfaction.
8. Putting It All Together: Business Impact & Risks
Implementing advanced RAG techniques is not just a technical upgrade — it unlocks business value, but also elevates risk.
Benefits include:
- Better factual accuracy and relevance in generated content → more trust from customers.
- Scalable knowledge systems that evolve over time with user feedback.
- Personalized and contextually aware AI assistants or agents.
- Differentiated GenAI offerings with strong governance and compliance.
Risks to manage:
- Retrieval hallucinations (irrelevant or harmful fetched context).
- Privacy leaks if retrieval corpus is not properly governed.
- Reinforcement models that drift or reward harmful generation.
- Infrastructure costs and complexity.
By architecting a robust system with proper indexing, reranking, agents, data governance, and feedback loops, you can mitigate these risks while maximizing the upside.
Conclusion
Building a production-ready RAG system is not a trivial task — it requires fine tuning at every stage: from pre-retrieval optimization, through retrieval and reranking, to post-generation feedback and governance. But when done right, advanced RAG techniques unlock generative AI’s full potential in business: they deliver more accurate, context-aware, and reliable outputs while preserving trust, scalability, and compliance.
By combining type-aware agents, robust data governance, continuous feedback loops, and smart infrastructure, you can create GenAI applications that not only answer questions — but do so responsibly, securely, and at scale. This is the future of enterprise AI built on a foundation of both innovation and integrity.
FAQs
Q1: What distinguishes RAG from a plain generative model?
RAG augments a language model’s generation by retrieving relevant external documents — so the answers are more factual and anchored in real data, rather than being purely generative.
Q2: Can RAG systems scale to enterprise volumes?
Yes — by using distributed retrieval frameworks (e.g., Elasticsearch or Faiss), indexed embeddings, and horizontal scaling, you can manage large corpora and high query throughput.
Q3: What is the role of AI agents in RAG applications?
AI agents orchestrate retrieval and generation workflows: retriever agents gather context, generators draft responses, and user-interactive agents incorporate feedback for continuous improvement.
Q4: How does data governance improve RAG quality?
With governance, you ensure data quality, access control, lineage tracking, and privacy compliance — which leads to more trustworthy retrieval and generation outputs.
Q5: Why use learning-to-rank models in post-retrieval?
LTR models refine and reorder retrieved documents by learning from relevance signals, enabling your system to surface the most useful, high-precision documents before generation.
Q6: Is reinforcement learning necessary in RAG post-retrieval?
Not strictly required, but reinforcement learning can greatly improve relevance and user satisfaction over time by optimizing retrieval/generation decisions based on real-world feedback.